20 March 2024 | FinTech
Credit Decisioning’s OS Moment
By Alex Johnson
Let’s start with an observation – the development of innovative technology tends to start out narrowly, focused on specific use cases and problems. However, what distinguishes truly disruptive technology is the transition that it makes from a purpose-built solution to a more generalized capability.
Take computers, for example.
In the early days of computing, machines were built to perform specific tasks, such as complex calculations or code-breaking (many of the first modern digital computers were built during WWII). These single-purpose computers were designed with specialized hardware and software tailored to their intended function. They lacked the flexibility to execute diverse tasks and required extensive reconfiguration to adapt to new requirements.
It took pioneers like Alan Turing and John von Neumann to see the greater potential hiding behind these machines. They envisioned universal computing machines capable of executing a wide range of tasks through programmability. This led to the development of stored-program computers, where instructions and data were stored in memory, enabling dynamic reprogramming and versatility.
Operating systems (OSs) emerged as a crucial component in managing resources, scheduling tasks, and providing a user-friendly interface to interact with the underlying hardware. Early operating systems like UNIX introduced concepts such as multitasking and virtual memory, laying the groundwork for the efficient utilization of computing resources and facilitating the development of complex software applications.
As computing power increased and hardware became more standardized, operating systems evolved to support diverse hardware architectures and accommodate a growing ecosystem of software applications. Graphical user interfaces (GUIs) further democratized computing by making it more accessible to non-technical users, ushering in an era of personal computing.
More recently, artificial intelligence (AI) has been undergoing a similar evolution.
Just as early computers were designed for specific tasks, traditional machine learning algorithms were tailored to solve narrow, well-defined problems, such as image classification or language translation.
However, recent advancements in deep learning and neural networks have led to the development of foundation models, such as OpenAI’s GPT models. These models are trained on vast amounts of data and can perform a wide range of tasks, including language generation, text completion, and image synthesis, with minimal task-specific fine-tuning.
Much like operating systems in computing, foundation models serve as the underlying framework for building diverse AI applications, offering a versatile platform for developers to create innovative solutions across various domains.
The details differ, but the underlying pattern is the same – technology is developed to solve specific problems, but it is later generalized in ways that provide significantly more value.
The challenge is that it can be very difficult, in the beginning, to appreciate just how much untapped potential a purpose-built technology may have.
Credit Decisioning
The first automated credit decision engines were built in the 1980s and early 1990s. The basic idea was to leverage software (first hosted on-premise and eventually in the cloud) to streamline specific steps in the credit decisioning process.
To understand these early systems, it’s helpful to first understand the process that they were trying to help automate.
Oversimplifying a bit, the credit decisioning process can be boiled down to these three steps:
- Develop a Lending Policy – The lending policy is essentially just a sequentially designed workflow of business rules that determines whether someone applying for a lending product should be approved for it. The policy reflects the nature of the product (its structure, compliance requirements, etc.) and the lender’s opinion on who should get it.
- Develop a Risk and Pricing Model – The heart of the lending policy is the model that determines if an applicant should be approved for a loan and, if yes, at what price. In the old days, the “model” was a loose set of guidelines that a loan officer would hold in their heads while manually decisioning applicants. Since the 1990s, the “model” has been a proper mathematical model, built using logistic regression or machine learning techniques. Today, risk and pricing models are typically built and maintained by data scientists and risk analysts.
- Decision Applicants – Once you have the lending policy and risk and pricing model built, you can use them to evaluate individual applicants for credit. The first step in this process is acquiring the data necessary for that policy and model to be applied. This data includes basic personally identifiable information (PII) like age (which drives simple decision steps in the workflow like, “Is this applicant old enough to enter into a legal contract?”) and more complex data like what’s found in an applicant’s credit report (which provides the raw data needed by the risk and pricing model). Once the data on a specific applicant has been acquired, the lender will evaluate it using its lending policy and risk and pricing model. 30 years ago, it was common for this decisioning process to be done manually by loan officers, either in the back office or sitting face-to-face with the customer. In modern times, this step is frequently (though not always) handled by automated systems.
These steps can be more accurately pictured as a loop, as lenders will take the outcomes from the credit decisions they make and feed them back into their lending policy and risk and pricing model in order to further refine them and adjust to changing market conditions.
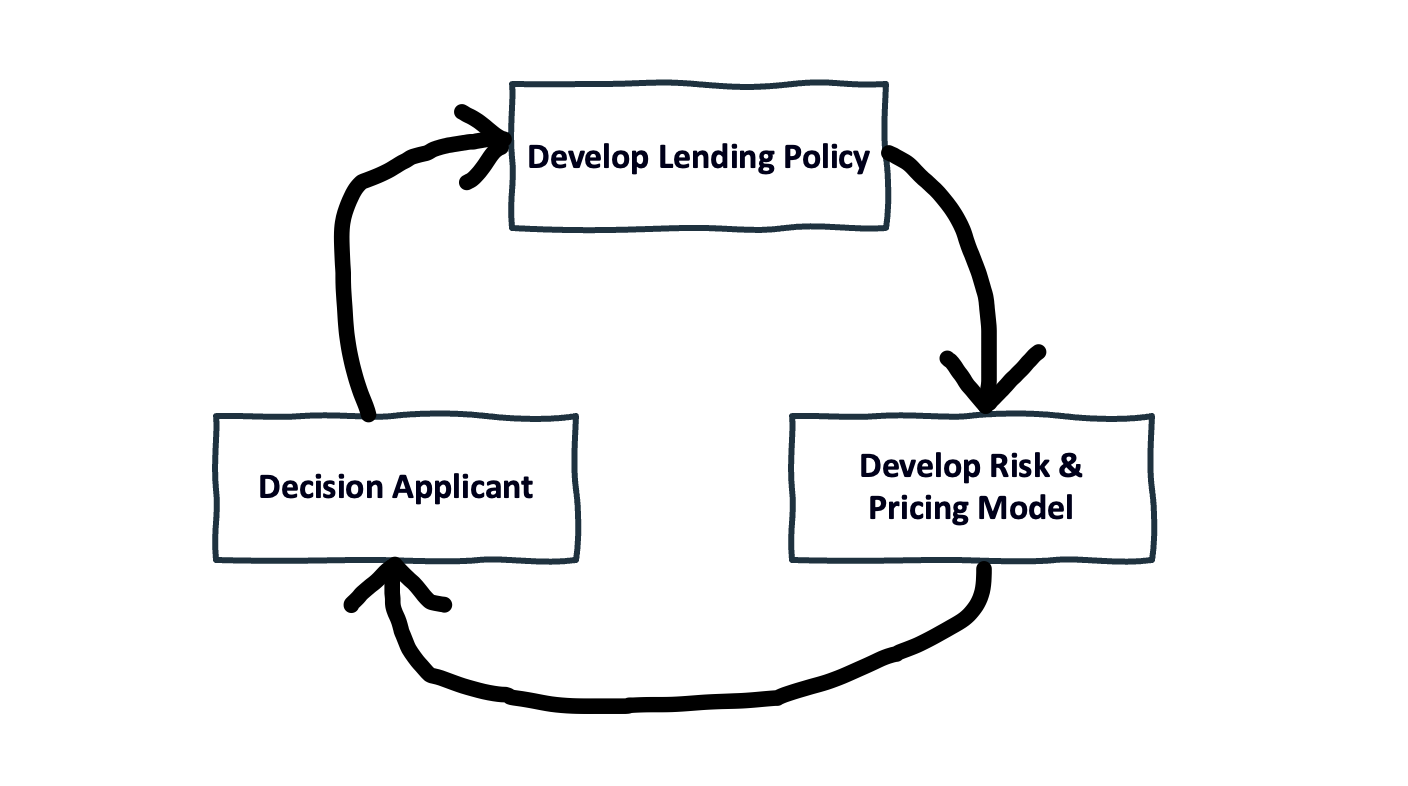
30 years ago, banks began to leverage credit decision engines to incrementally improve specific steps within this credit decisioning process.
This felt revolutionary at the time (trust me, I was there), much, I’m sure, as early purpose-built computers felt to those who used them to crack enemy codes or calculate firing solutions for submarine torpedoes.
However, what we didn’t realize at the time was that these credit decision engines were doing very little to help banks meaningfully differentiate themselves.
Three Decades of Bank Differentiation
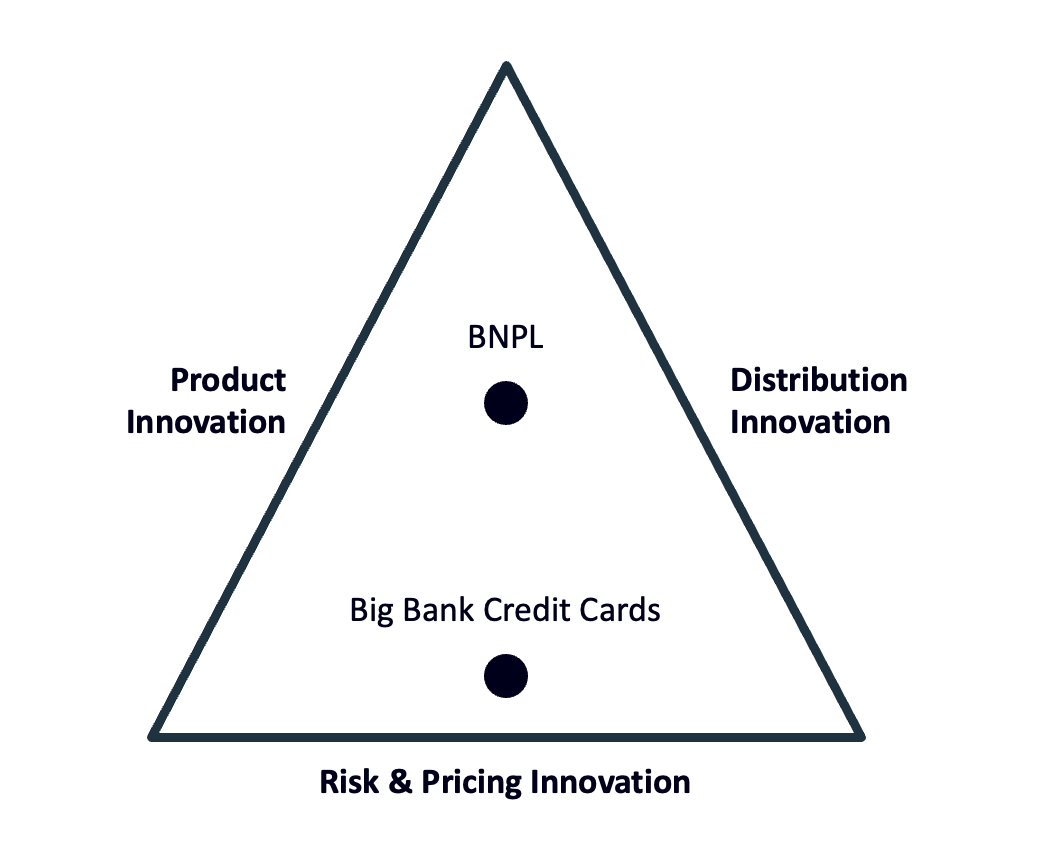
Here’s a simple model for how lenders differentiate themselves:
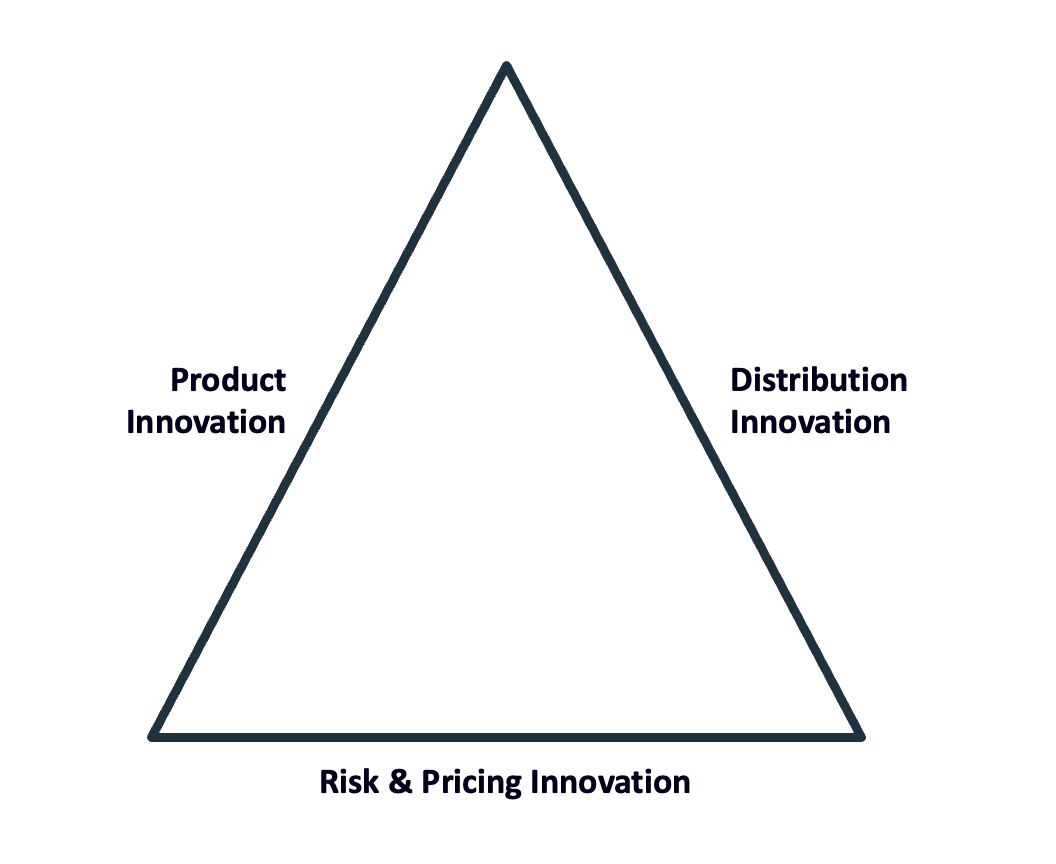
Differentiation through product innovation – building novel lending products that better meet the needs of specific customer segments – has always been difficult for banks. The regulatory and reputational incentives to stick with tried-and-true product templates are incredibly strong, and they have mostly kept banks from coloring too far outside the lines.
Differentiation through distribution innovation – cost-effectively acquiring unique and valuable segments of customers – was the primary strategy for most banks, until digital banking started picking up steam in the early 2000s (at the expense of branches).
This left differentiation through risk and pricing innovation – using advanced analytics to more accurately price the risk of default – which is exactly where forward-thinking lenders, following in the footsteps of Capital One, went, beginning in the mid-90s and continuing through to today.
To build up this muscle, banks primarily invested in people, hiring Ph.D. statisticians, data scientists, and quantitative risk analysts.
And to shore up the remainder of the credit decisioning process, to ensure that it would be able to support the brilliant risk and pricing models designed by their experienced and expensive credit risk teams, banks adopted point solutions for credit decisioning – developing and managing lending policies (using business process management engines like Pegasystems) and acquiring data and executing real-time decision rules (using business rules management engines like FICO Blaze Advisor).
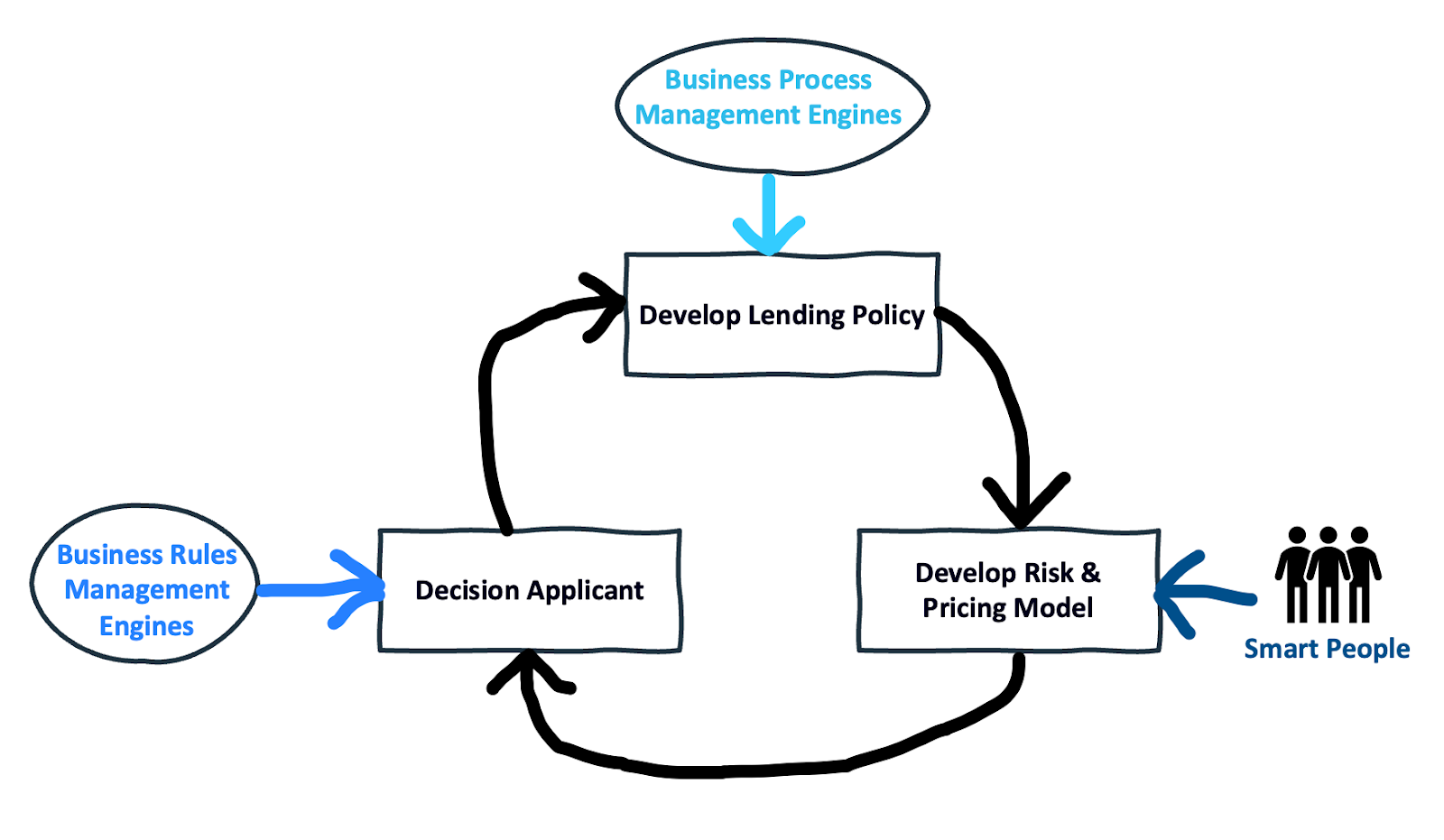
This has been the status quo in the lending industry for quite a few years, and it has worked out reasonably well overall (give or take a couple of financial crises).
However, it has become increasingly evident to me that we’ve squeezed about as much out of this model as we can.
What’s the Problem?
Two things.
First, the let’s-be-smarter-than-everyone-else-on-credit-risk strategy (AKA the Capital One strategy) is starting to show diminishing returns. There’s only so much performance lift you can wring out of the same data sets (credit files, internal performance data, etc.), and, as I have written about before, there will always be societal limits on the scope of the data that we allow lenders to use to make credit decisions. Throwing more data scientists at a question that you already have a good answer to isn’t going to magically produce an even better answer. It’s just going to raise your costs.
Second, patching together various point solutions within your lending infrastructure, while expedient and cost-effective in the short term, has a significant downside.
Remember, a well-functioning credit decisioning process isn’t a waterfall of linear steps. It’s a loop. Lending, as I am fond of saying, is a learning business, and the most successful lenders are the ones that can build the tightest loops, allowing them to iterate and learn the fastest.
The evolutionary path of bank lenders has not produced tightly integrated, highly iterative credit decisioning environments. Instead, it has given banks something like this:
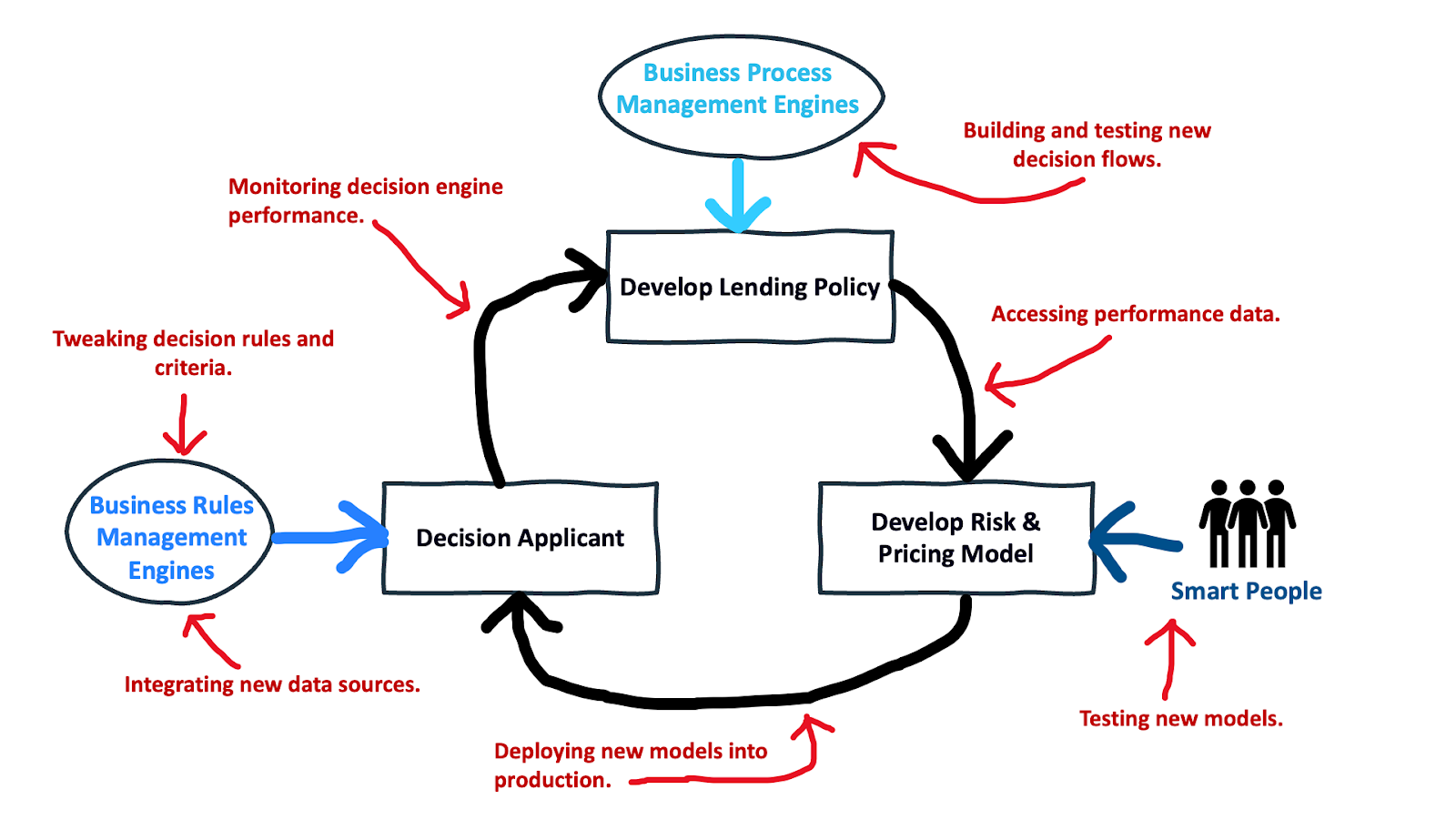
You want to build and test a new decision flow? Feel free to sketch it out on your whiteboard, but you’ll have to wait months to get the engineering resources necessary to actually implement it. You want to access clean, well-structured performance data to build your model? Get in line. How long will it take to get that new model of yours into production? The over/under is 10 months. How about integrating a new data source? That’ll be one year and one million dollars.
You get the idea.
Purpose-built credit decision engines provided a lot of value to lenders 30 years ago, but today they’ve created a bit of a mess.
So, what’s the solution?
Credit Decisioning OS
Like the development of computers and AI, credit decisioning has begun to evolve from a series of point solutions into something more universal.
When I worked in the credit decisioning space 20 years ago, we were big proponents of this evolution. Rather than being highly prescriptive in building the technology to support a specific use case, we tried to look for the common functional requirements sitting beneath every use case and then build the most generic (but robust) components possible to support each required function.
We boiled it down to six boxes – a business user tool and corresponding run-time service across data access, business rules and processes, and user interfaces – which we thought would be capable of supporting any decisioning process for any type of lending product.
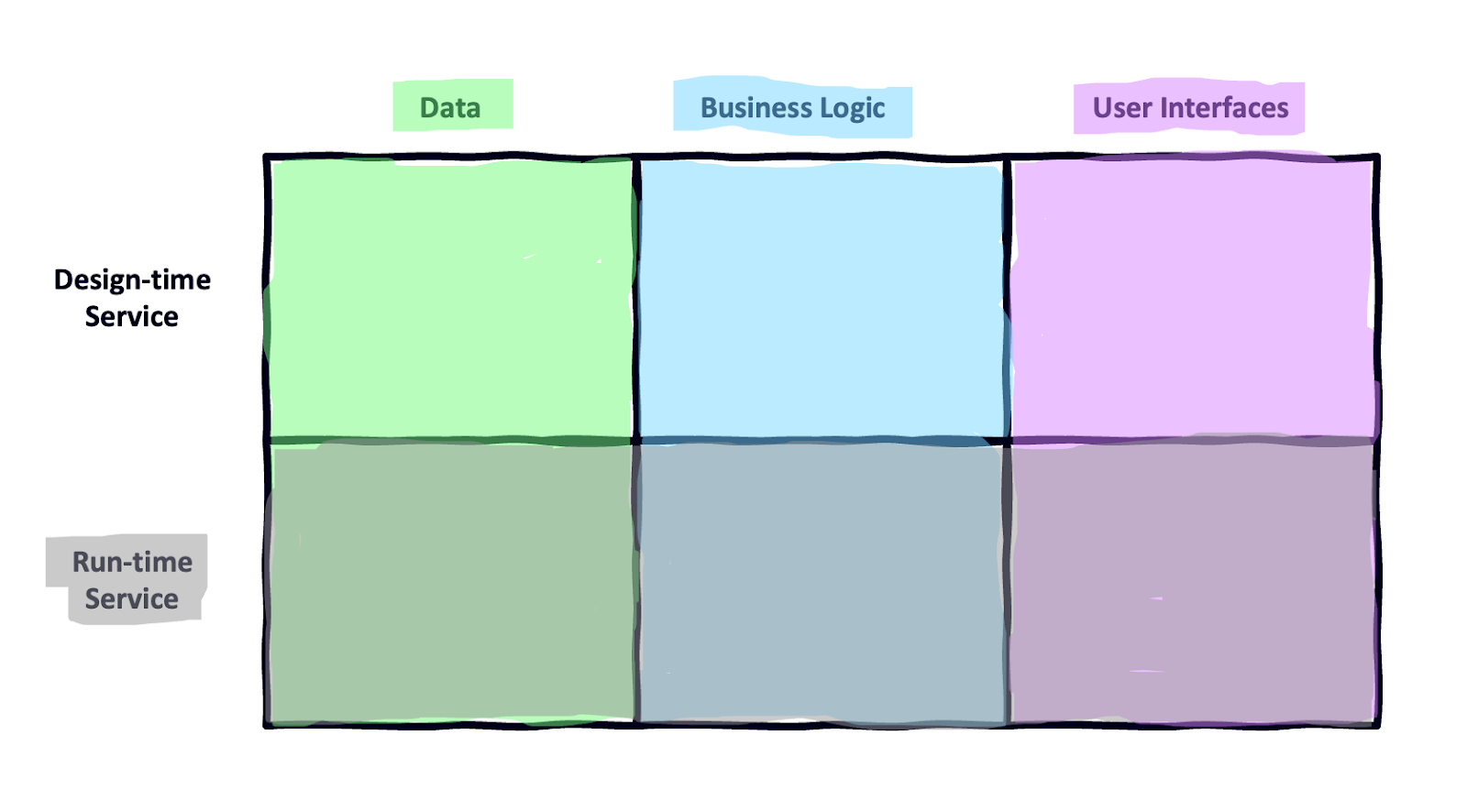
It was a neat vision, but we were too early. In those days, the only companies to sell credit decisioning to were the big banks, and they didn’t have the appetite to rip and replace the entirety of their credit decisioning infrastructure to build a more agile and iterative environment. They just wanted point solutions to enhance the efficiency and profitability of their existing processes.
This is where fintech comes in.
A fintech lending company being built today has the opportunity to leverage next-generation credit decisioning software (built on modern technologies and designed to be configurable without the need for engineering resources) to design a tightly integrated and highly iterative environment for designing and launching lending products.
Let’s call it a Credit Decisioning OS:
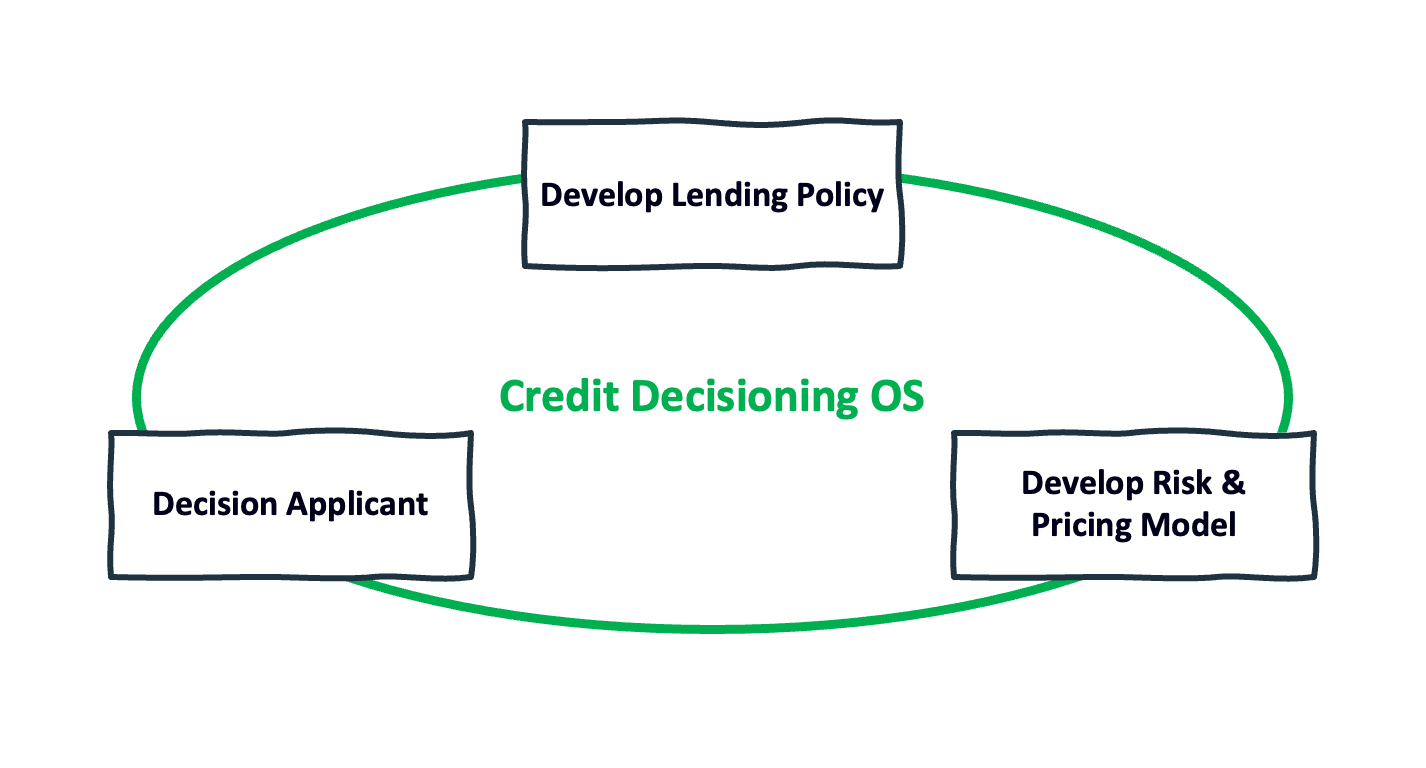
This type of fully integrated decisioning environment enables lenders to be much more balanced in their pursuit of competitive differentiation. Rather than having to make a big bet in a single area, a lender building within a Credit Decisioning OS could pursue multiple avenues of differentiation simultaneously.
BNPL is a good example. While large credit card issuers were busy trying to squeeze a few more basis points of losses out of their portfolios with their incredibly sophisticated risk-based pricing algorithms, early pioneers in the pay-in-4 BNPL space were innovating on product (pay-in-4 is an entirely new product construct), distribution (integration within the e-commerce checkout flow), and risk and pricing (underwriting credit lines for credit invisible consumers) all at the same time.
Agility Wins
It’s trite to say that in technology, speed wins. But just because it’s trite, doesn’t mean that it isn’t true. The reason that VC investors value tech startups that constantly ship code so much is because that trait is highly correlated with success. Companies that are always shipping are more likely to create value for their customers and more likely to see that value compound quickly.
A similar dynamic is becoming increasingly evident in lending.
In a recent survey of credit risk executives, Taktile asked respondents how close they are to achieving their strategic objectives across various performance metrics, including customer conversion rate and customer default rate.
Unsurprisingly, most respondents indicated that their organization has at least some ways to go to meet its strategic objectives.
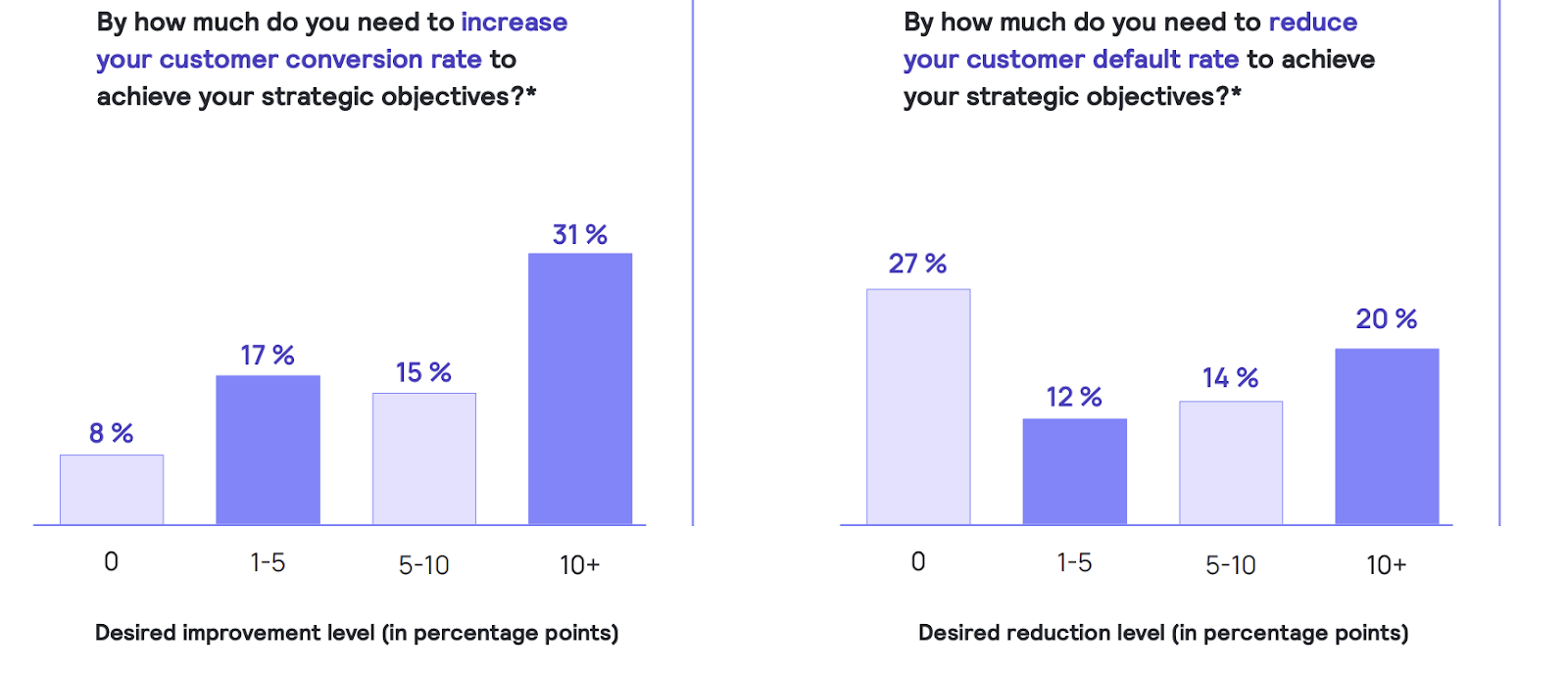
What’s interesting is what the top performers – those who indicated that they required little to no improvement in order to meet their organization’s strategic objectives – had in common.
According to Taktile’s survey, the lenders that were least likely to report needing a significant improvement in customer default rate (i.e. those with the best performance), were far more likely to report that they are capable of adjusting their credit policies within hours or days rather than weeks or months.
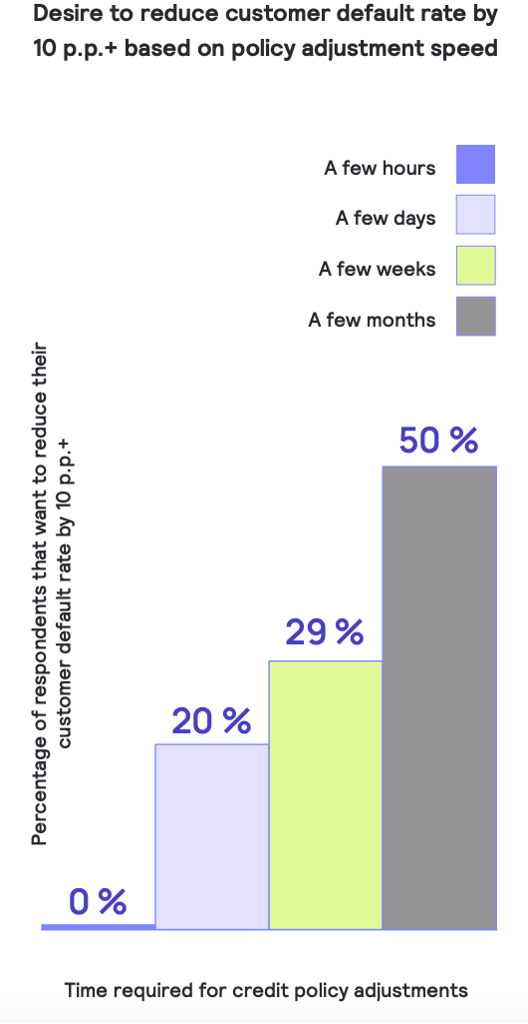
Looking at customer conversion rate, it’s the same story. Lenders who adjust their credit policy on a weekly basis are half as likely to report needing to significantly increase their customer conversion rate in order to hit their strategic objectives.
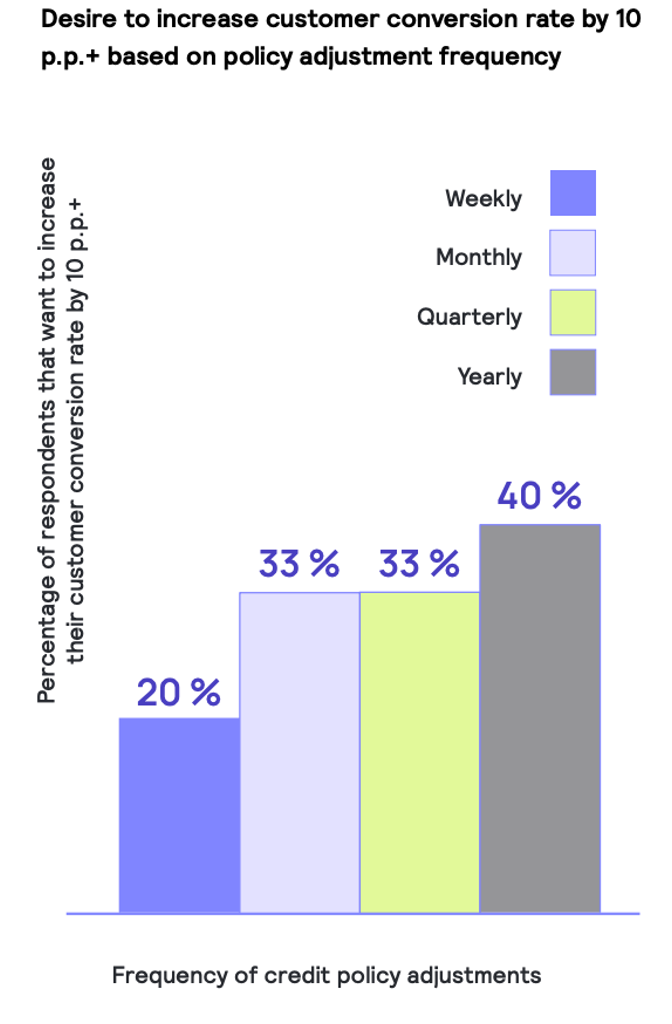
What does this data tell us?
It tells us that lenders that utilize modern credit decisioning technology to its fullest disruptive potential – to unlock organizational agility – are able to iterate faster, learn quicker, and, ultimately, separate themselves from their peers across every facet of competitive differentiation.
This was always the evolutionary destiny of credit decisioning, as a technology.
It just took us a while to get here.
About Sponsored Deep Dives
Sponsored Deep Dives are essays sponsored by a very-carefully-curated list of companies (selected by me), in which I write about topics of mutual interest to me, the sponsoring company, and (most importantly) you, the audience. If you have any questions or feedback on these sponsored deep dives, please DM me on Twitter or LinkedIn.
Today’s Sponsored Deep Dive was brought to you by Taktile.

Taktile is the next-generation credit decisioning software that is redefining how banks and FinTech companies approach credit risk assessment, onboarding, fraud detection, and dynamic pricing.
Trusted by companies like Branch, Novo, Rhino, and Kueski, Taktile’s decision engine seamlessly adapts to any use case – empowering risk teams to quickly build, run, and optimize automated risk decisions without engineering support.
Leveraging its comprehensive Data Marketplace of third-party integrations and state-of-the-art experimentation features, companies can expedite the launch of new financial products, enhance risk and pricing precision with ease, and rapidly implement policy changes.