
Our premise for today is simple – Disruption in financial services tends to occur when technology innovation intersects with a significant regulatory shift.
The last time this happened was in 2010, when this:

Gave us this:

As many others have written, it was the combination of smartphones and the Durbin Amendment that led to the creation of much of what we consider to be the modern fintech landscape. And not just the consumer-facing neobanks and online lenders, but also the BaaS and fintech infrastructure sitting underneath those companies and the B2B fintech providers that modeled many of their product design patterns on the B2C products that preceded them.
And I think the most important question in financial services is, what’s next? What will spark the next great wave of disruption in financial services?
Crypto!
Just kidding 🙂
I actually think it will be generative AI + open banking.
Now, I know those are two very buzzy buzzwords, which are often used (and misused) in different ways. So let’s try to be as precise as we can in describing what they are and how the combination of them has the potential to dramatically change the financial services industry.
Let’s start with generative AI.
A Tiny Bit Closer to General Intelligence
Here’s a definition of generative AI that I like:
Generative AI is a new field of artificial intelligence that aims to model and understand data distributions allowing it to generate new samples from that distribution. Instead of just finding patterns or making predictions like many traditional machine learning models, generative models focus on understanding and replicating the underlying structure of the data to produce new, similar data.
Put simply, you give a generative AI model a large dataset and it will figure out the structure and patterns within that dataset and how to replicate similar data based on prompts from users.
Why is everyone so excited about this?
Well, mostly, it has to do with how different generative AI is from traditional machine learning models.
Traditional machine learning models can produce some outstanding results, but the models themselves are rather persnickety. This quote from Kalev Leetaru sums this up rather well:
Join Fintech Takes, Your One-Stop-Shop for Navigating the Fintech Universe.
Over 36,000 professionals get free emails every Monday & Thursday with highly-informed, easy-to-read analysis & insights.
No spam. Unsubscribe any time.

The vast majority of magic, most magicians would tell you, is rather mundane. It’s practicing rote physical movements and routines thousands of times until they are second nature. It’s spending hundreds of hours designing props and a stage to be just right so that the audience will be able to suspend their disbelief for the 3 minutes that it takes a magician to perform their act.
Data scientists working inside large banks will tell you a similar story. The majority of what they spend their time doing isn’t data science, it’s engineering. It’s doing the mundane and deeply frustrating work to access data from a variety of different internal sources, clean, categorize, and structure that data, and ensure that their resulting models are deployed in a way that produces the outcomes they expect.
Due to the inherent difficulty of building and deploying machine learning models in banking, there are a lot of use cases that make sense on paper, but that don’t actually end up making it into production. The juice just isn’t worth the squeeze.
Generative AI is different. You don’t have to feed it meticulously clean and well-categorized training data. It’s not looking for patterns within the data. It’s looking to understand the structure of the data itself.
As such, you can feed it unstructured data.
As much of it as you want.
In fact, the more, the better.
This is exactly what companies like OpenAI – the maker of ChatGPT – are doing.
GPT-4, OpenAI’s latest model, was trained on a dataset that is roughly 1 petabyte in size. By contrast, the previous model (GPT-3) was trained on a dataset of about 45 terabytes.
(For reference, a petabyte is 1,024 terabytes.)
Why is this important?
Well, in generative AI, size matters.
Here’s how all of OpenAI’s models perform against each other in a test designed to measure the accuracy of the model’s answers to questions across a wide range of fields and disciplines:
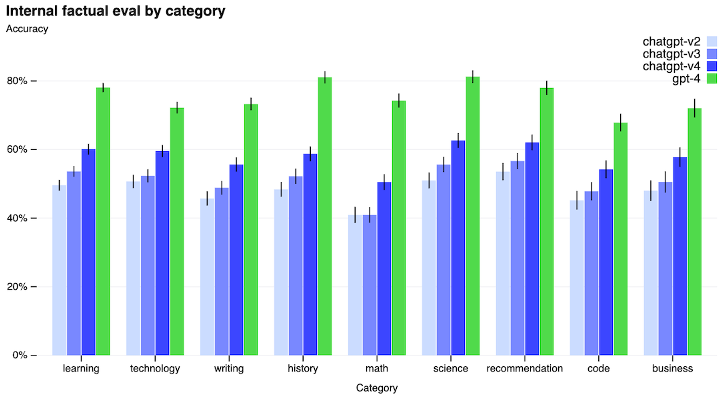
GPT-4 performs substantially better!
And if you zoom in on an even more specific example, it gets even more impressive. According to OpenAI, GPT-4 passes a simulated bar exam with a score around the top 10% of test takers, while GPT-3.5 scores in the bottom 10%.
To be clear, this isn’t true artificial general intelligence (AGI). It’s not Skynet. However, the reason that data science researchers are so excited about generative AI (and, in some cases, freaked out) is that it’s much closer to artificial general intelligence than anything else we’ve ever built.
It’s essentially a generalized reasoning engine that is trained on the patterns inherent in the way that human beings organize and communicate meaning.
That’s pretty cool!
But How Might We Use it In Financial Services?
To answer this question, we first need to understand how banks and other financial services providers make decisions.
Every decision in financial services is the output of some combination of predictive models, decision rules, and human reasoning and judgment.
Over the last 30-40 years, we’ve made significant progress in moving decisions away from humans and towards predictive models and decision rules. This is an important accomplishment. It has lowered costs and led to more consistent and less biased decisions.
However, there is a natural limit to how far we can push the boundaries on automated, rule-driven decisioning.
A few years ago, I worked on a project with a top-10 U.S. bank that wanted to build a universal decision engine that would sit across every channel and line of business at the bank and would automatically be able to determine the next best action for each customer during every customer interaction.
It was a very ambitious project, with very obvious benefits, but it was also enormously complex. They had to essentially document how every customer-facing decision at the bank was made and then distill all of those different processes and bits of tribal wisdom down into a single, massive decision tree.
Basically, this, but a trillion times more complex:
It didn’t work. After spending $500 million and five years, the bank abandoned the project and fired the executive who was in charge of it.
What I learned from this experience is that there is always a level of human reasoning and judgment that is required to make banks’ decision-making processes run smoothly and predictably.
This isn’t to say that humans are perfect.
Far from it!
Humans don’t have good memories. We get tripped up by simple arithmetic problems. We’re not especially fast at processing information or making decisions. We carry around a ton of biases in our brains that we’re mostly not even aware of. And we constantly get tired, bored, and distracted.
However, one thing that we’re uniquely good at is applying a broad range of experiences and knowledge to solve new problems.
Put simply, we’re great at edge cases.
Generative AI is similar.
It doesn’t have a good memory (try playing Hangman with ChatGPT sometime). It can be easily fooled by simple math questions. It’s slow (Google’s integrated generative AI chatbot is MUCH SLOWER than the regular search results). And, because they are trained on data scraped from the internet, generative AI models are, of course, biased.
However, generative AI models are good at solving new problems through generalized reasoning, based on the broad experiences and knowledge that they have been exposed to through their training data.
And bonus! They don’t get tired or bored or distracted!
So, while we can’t necessarily remove the need for reasoning and judgment in banks’ decision-making processes (especially for edge cases), we can potentially remove (or at least reduce) the need for human reasoning and judgment in those processes, thanks to generative AI.
Where Should We Plug It In?
Generative AI is best thought of as an intern.
An intern who is inexperienced, overeager, tireless, and never bored or distracted.
It makes mistakes because there’s just a lot of stuff it has never seen before. It’s also so eager to do a good job that it will frequently lie to you when it doesn’t know the right answer.
But it’s smart. It can problem solve. And it’s relentlessly cheerful and hardworking.
Except, of course, it’s not a person.
It’s a service. You can call it via an API.
It’s Inexperienced-Overeager-Tireless-Never-Bored-Intern-as-a-Service (IOTNBIaaS).
So, the question is, where exactly should we plug in IOTNBIaaS?
There are three areas where I would look:
- Wherever low-level human judgment is required. Generative AI can’t replace deep subject matter expertise (at least not yet), but it can sub in wherever you need a low level of generalized intelligence and judgment. For example, in business lending, the way that you traditionally verified many of the details of a brick-and-mortar business was to conduct an in-person site visit (does it look like there’s a pizzeria at this address?) When B2B fintech lenders first came on the scene, they reduced the cost of this site visit step by plopping a human down in front of a computer and asking them to make the same determination by looking at Google Street View. This was a massive improvement, in terms of cost and efficiency, but it still wasn’t perfect. Lenders still had to have humans making that determination. It’s not like it was a complex determination to make (my five-year-old could be taught to do it), but it was just broad and nuanced enough to make it impossible for an optical character recognition (OCR) model to handle. Generative AI can do this job today.
- Wherever unstructured data can provide value. Banks’ historical aversion to unstructured data (due to their inability to efficiently extract insight from that data) no longer makes sense in a world populated by generative AI models. Thus, where I would look for opportunities to plug in generative AI would be in any of the unstructured sources of data that banks have or can get their hands on. Compliance and customer service are two specific areas that come to mind.
- Wherever multiple ‘agents’ are involved in a decision-making process. One of the challenges in distilling down all the decisions that a bank makes into a set of if/then rules is that a lot of those decisions are the result of multiple people inside the bank, each with their own experiences, viewpoints, and incentives, interacting with each other (sometimes adversarially). That’s impossible to replicate with traditional machine learning and decision rules, but it may be possible with generative AI. Imagine being able to spin up AI ‘agents’ that represent distinct viewpoints and roles within a bank and designing decision-making processes around them that mirror the processes that the people in the bank use today. For example, instead of budget planning happening once a year and then spinning out of control as soon as all the executives walk out of the room, what if you could have an ongoing, AI-powered budget planning process running continuously throughout the year, helping the human stakeholders stay aligned as the company’s goals and financial condition changes.
What will be the benefits of plugging generative AI into these use cases? There will be many, I imagine, but these three are at the top of my list:
- Costs will go down significantly. There is so much low-value work done by humans in the back offices of banks. Some are bank employees who would prefer to do more meaningful and important work. And some work for business process outsourcing (BPO) firms like Accenture, Capgemini, and Wipro (BPO is a $260 billion market growing at a nearly 10% CAGR … check out this Simon Taylor rant to dig more into gen AI’s potential to disrupt the BPO market). A lot of this can be eliminated with generative AI. Document processing is a good example. OCR has been very useful in financial services, but it requires a lot of specialized training and human oversight. Generative AI is going to be vastly better at document processing because it can deal with a wide range of different document types, and it won’t get flustered by weird edge cases.
- Generative AI is also going to make humans much more efficient. This will happen at an individual level (copilot for X), but it will also happen at a team level. Imagine having an AI loan committee that can assemble all of the necessary information for a new commercial loan and hash out all the details (from a variety of different perspectives) before the human loan committee meets.
- Entirely new use cases will suddenly become viable. By lowering the costs of tasks that otherwise would have required humans, generative AI will create entirely new automation use cases. For example, most compliance monitoring at banks works via sampling – picking out a small number of cases randomly and then having a human review them to make sure everything looks good. This isn’t the optimal way to ensure compliance. The optimal way to do it is to monitor everything in real-time, but that’s not practical for a use case like compliance, where there is lots of unstructured data and nuance that require humans to parse. With generative AI, we can potentially make that optimal approach cost-effective.
Of course, none of this is certain. Generative AI is a brand new field, and it has been absolutely overrun by speculation, hype, and nonsense. It’s difficult to tell exactly what’s real and what’s bullshit right now. And there are some legitimately hard problems to be solved before any of these benefits can be realized. Here are three that I have been thinking about a lot:
- We don’t tolerate machines making mistakes. The concern here is hallucination. It’s unnerving watching ChatGPT cheerfully make up realistic-sounding scientific papers as sources. Researchers are working on ways to limit the harm caused by hallucination, but I personally doubt it’ll ever be a problem that is completely solved. These models are probabilistic. Educated guesswork will always be an inherent trait. But, of course, that’s true with humans too! Humans make bad guesses and treat their hunches like facts all the time! The difference is that our society has a much higher tolerance for humans making mistakes than we do for machines making mistakes. That’s why self-driving cars will need to be basically perfect before they will see wide adoption. We just aren’t comfortable with the idea of machines randomly killing us, even if they are less likely to do so than our fellow humans. It will take a lot of time for generative AI to get past this concern, which is why I see most applications being focused on back-office rather than customer-facing use cases for the foreseeable future. Also, I’m just telling you now, regulators are not wild about generative AI. Building up their comfort with the technology is going to take a TON of work.
- Latency and cost are ongoing concerns. Automated decisioning processes aren’t very tolerant of costs (wrecks the ROI) or latency (wrecks the experience), and right now, generative AI is slow and expensive if banks want to use the latest and coolest stuff. Have you ever tried GPT-4? Open AI is charging users $20 a month, and it’s … not fast. Now, if banks wanted to use an older version, they could optimize for latency and cost, but they don’t want to do that … at least not yet. The performance gains they get from the newest model are just too good. So, banks need to solve this engineering challenge another way. Can you help the gen AI model narrow down the search space? Can you, after seeing enough interactions with the gen AI model in a very specific use case, start to predict its response with acceptable accuracy? These are the types of engineering questions that folks working in this space are asking right now.
- Generative AI is smart, but it lacks context. This is perhaps the biggest issue for financial services (and other highly specialized and heavily regulated fields like healthcare and the law) – these generative AI models often lack sufficient context to generate the best possible responses. Go back to the intern analogy. These models have never “worked” in financial services before. They have none of that experience. All they know is what’s on the internet, and most of the really useful knowledge and experiences in financial services aren’t available on the internet. It’s locked in private databases and in the heads of people who’ve been working in this industry for decades. These models are going to get smarter as we add in more data, and they will become more capable once we connect them with the tools that they need to augment their intelligence (connecting chatbots to search engines is the logical starting place), but the context problem will continue to be an issue.
Let’s double-click into that last problem.
How Do We Give Generative AI Models More Context?
This is where we circle back to open banking.
In the interests of clarity, here’s how I define open banking:
Open Banking is the trend of making consumers’ financial data portable with the intention of unlocking data-driven innovation and increasing competition. In the U.S., open banking has, so far, been driven by the private sector (via screen scraping), but it’s about to become a formal regulatory requirement (courtesy of the CFPB’s recently released rules).
How does open banking help us provide generative AI with more context?
Open banking is going to make it possible for a bank’s customers to provide it with data that it doesn’t already have, which can then be used to provide more context to the bank’s generative AI models.
In the short term, this will mean giving banks a more comprehensive picture of their customers’ financial lives through structured data, piped in from those customers’ other financial services providers. Generative AI will be a flexible tool for enriching and interrogating this data, and, potentially, a new interaction layer for the customer (Mike Kelly built a ChatGPT plugin called BankGPT to demonstrate what this could look like).
In the long term, it will get even more interesting. Today, open banking revolves around structured data (transactions, balances, interest rates). That’s mostly a function of the data that aggregators could get access to through screen scraping and the inability of traditional machine learning models to deal with anything else.
But there’s really no reason that the essential regulatory intent of open banking – any financial data relating to the customer is the customer’s data, and they can share it with whomever they choose – couldn’t one day be applied to unstructured data. Why, for example, shouldn’t a customer be allowed to share the images of all the checks they’ve ever deposited in their deposit account? Or the complete transcripts of all the customer service interactions they’ve had with their bank?
Historically, banks and fintech companies had no interest in acquiring this data because, practically speaking, there was nothing that they could do with it.
With generative AI, that’s no longer true.
Chocolate and Peanut Butter
I’ll leave you with this question:

I don’t know the answer. I doubt anybody does … yet.
It’s still too early.
But I’m becoming increasingly convinced that this is the question that will define, for better and for worse, the next decade of innovation in financial services.

