
ChatGPT, OpenAI’s chatbot powered by generative AI, reached 100 million global monthly active users in just two months, which was seven months faster than any other consumer technology product in history.
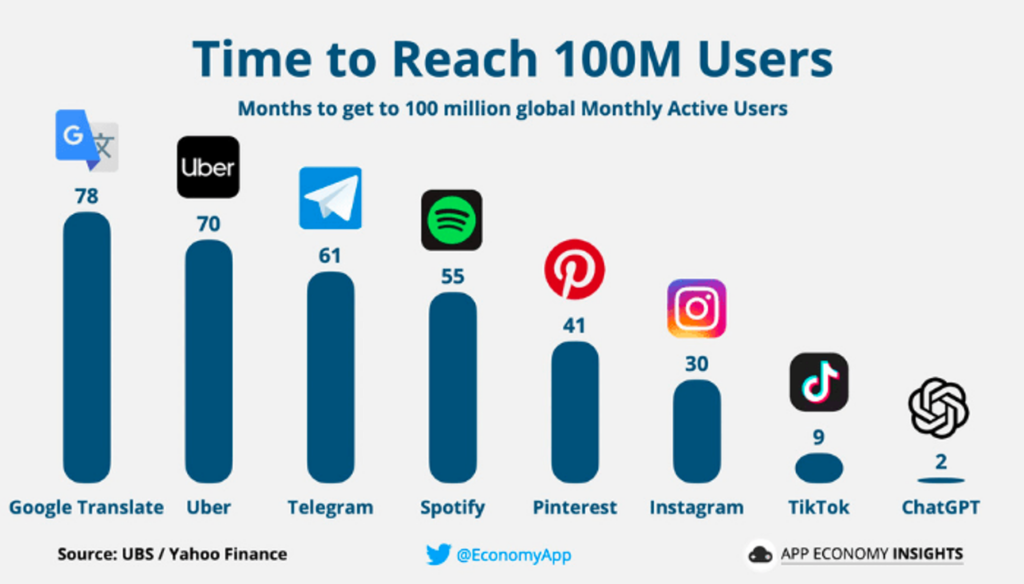
(For the purposes of this essay, kindly ignore the fact that Threads, Meta’s soulless Twitter clone, has since beaten this record by reaching 100 million users just five days after launching. Thank you.)
Given this level of adoption and the surprisingly broad capabilities of ChatGPT, it’s not surprising that consumers have been experimenting with it for all kinds of tasks, including getting financial advice.
According to a recent survey from The Motley Fool, 54% of U.S. consumers have used ChatGPT to recommend a financial product, such as a credit or debit card, bank account, broker, mortgage lender, insurance provider, or personal loan.
A different survey, also from The Motley Fool, found that 47% of U.S. adults have used ChatGPT for stock recommendations.
And while I doubt that ChatGPT did an especially good job recommending financial products or picking stocks (remember – ChatGPT is trained on a data set that is several years old, so giving up-to-date recommendations isn’t really in its wheelhouse … yet), consumers seem bullish on the technology. According to a survey from the Nationwide Retirement Institute, 31% of U.S. consumers feel ChatGPT will provide better financial advice than a human financial advisor in the next five years. That percentage jumps up to 37% for Gen Z and a whopping 43% for Millennials.
This optimism is, to put it mildly, not shared by those human financial advisors:
“It is by no means going to provide you with a way to beat the market,” Douglas Boneparth, a certified financial planner and the president and founder of Bone Fide Wealth, tells CNBC Make It. Boneparth himself put ChatGPT’s financial acumen to the test and says the results weren’t great. He asked the tool to build him a hypothetical diversified portfolio with 80% equity and 20% fixed income and gave it a few parameters, risk characteristics and guidance as to what kind of exchange-traded funds (ETFs) he wanted to use. “I was presented with a table that added up to more than 100%,” he says. After informing ChatGPT of this, it tried to correct the error but didn’t necessarily pull the right information, he says.
What Mr. Boneparth is referring to here is hallucination, the tendency of large language models (LLMs) like GPT-4, which ChatGPT is built on top of, to occasionally produce responses that aren’t accurate or factual.
That’s obviously not ideal. And the concern with generative AI, as a field, is that a certain amount of hallucination is endemic to the technology.
An LLM is trained on vast amounts of unstructured data scraped from the internet. The model parses the training data in order to learn the patterns and associations contained within it. The model then uses those patterns to predict what the right response would likely look like, based on the prompt it is given.
The key word there is “predict”. Generative AI models aren’t deterministic. They are probabilistic. They’re not trying to derive the correct answer using a set of established rules. They’re trying to guess what the correct answer might look like based on the patterns they’ve observed within their training data. And that leads them to occasionally hallucinate plausible-sounding answers that aren’t actually correct or present in their training data, like producing a table with figures that add up to more than 100%.
Not ideal, especially in financial services, where we have a pretty high bar when it comes to accuracy and consistency.
That said, I don’t think we should write off the potential for generative AI to play a role in helping consumers make smart financial decisions. I just think we need to put the technology – its benefits and flaws – in the proper context.
Democratizing Access to Expertise
Let’s start here – as a general rule, I think humans tend to trust experts more than we trust regular people, and we tend to trust regular people more than we trust machines.
Driving is a good example.
Join Fintech Takes, Your One-Stop-Shop for Navigating the Fintech Universe.
Over 36,000 professionals get free emails every Monday & Thursday with highly-informed, easy-to-read analysis & insights.
No spam. Unsubscribe any time.
If Lewis Hamilton is chauffeuring you across Los Angles, you’re likely to be very relaxed and confident that you’ll get there safely. If it’s a random Uber driver, you might be slightly more anxious, but you’d still trust them. If it’s a fully self-driving car, you’re terrified.
This isn’t always entirely rational. As an expert, Lewis Hamilton might feel comfortable taking risks that are a bit excessive. And, objectively, self-driving cars are already better drivers than the average human in certain situations (and are likely to continue improving). But still, the hierarchy of Expert > Regular Person > Machine tends to remain the default for most people.
Here’s the problem, though – experts are inconvenient.
Experts are a pain to deal with. They generally don’t communicate well. They speak in jargon. They equivocate and constantly change their minds. And, because there aren’t a lot of them and their expertise is in demand, they aren’t very accessible. Lewis Hamilton doesn’t have time to chauffeur you across LA, and if he did, you wouldn’t be able to afford him.
Thus, over time, society has come up with lots of mechanisms to make expertise more accessible. We’ve figured out a myriad of ways to leverage regular people and machines to help translate and disseminate expert knowledge.
One of the most efficient mechanisms that we’ve come up with is the internet.
Examples of how the internet has democratized access to expertise abound, but I want to focus on three:
- Wikipedia. The goal of Wikipedia, according to its co-founder Jimmy Wales, is to create “a world in which every single person on the planet is given free access to the sum of all human knowledge.” A lofty goal, but one that Wikipedia has arguably achieved. The website has versions in 334 languages and a total of more than 61 million articles. It consistently ranks among the world’s 10 most-visited websites, despite being the only one in the top 10 that is produced by a non-profit organization. And it has done all of this via crowdsourcing – the practice of gathering information or input into a task from a large, distributed group of people. Wikipedia’s unpaid contributors (the English-language site alone has about 40,000 active editors) essentially act as a volunteer corps of knowledge translators, converting dense, inaccessible expert knowledge into a consistent and readable format.
- Social Media. Compared to the noble mission and non-profit status of Wikipedia, I know that social media feels like an incongruous inclusion on a list of technologies that have democratized access to expertise. But I think you can easily make the case that social media has had as big (or bigger) an impact on the dissemination of knowledge as Wikipedia because, to put it bluntly, social media is more fun. It’s more fun to follow anonymous industry experts like Car Dealership Guy on Twitter than it is to read a Wikipedia article about auto lending. And it’s more fun to watch an unboxing video for the latest iPhone on YouTube than it is to read a dry spec sheet online. The fun, authentic, and engaging nature of social media is like a spoonful of sugar, helping the expert knowledge medicine go down. This partially explains why social media is vastly more popular than Wikipedia, comprising a full 50% of the world’s 10 most-visited websites.
- Generative AI. While it’s still very new, I think that generative AI has the potential to be the most accessible interface to expert knowledge ever invented. There are two reasons for this. First, natural language is an incredibly intuitive interface. Searching for specific knowledge is hard. We take for granted how good we’ve all gotten at using search engines and framing our questions in terms of keywords, but that’s not the way that humans naturally think. We think like we talk. Thus, being able to talk to a chatbot and be understood (or, at least, being given the appearance of being understood) is extremely powerful. Second, generative AI is an infinitely flexible translator, which means that we can get responses from it that are tailored to fit exactly within the way that we learn best. If you’ve ever used ChatGPT to help you explain complex topics to little kids, you know exactly what I’m talking about.
What’s interesting about these technologies is that they don’t exist in isolation, but rather build on each other, like blocks in a pyramid.
A large portion of the training data for GPT-4 came from social media (this has become a point of contention between OpenAI and the social media companies) and Wikipedia (which is estimated to be the single biggest contributor to the scraped data that an LLM uses for training, between three and five percent).
Social media is similarly dependent on Wikipedia, as anyone who has come across a viral thread boi thread on Twitter can attest to.
And Wikipedia, while acting as the foundational knowledge layer for the internet, is, itself, built on top of expert knowledge, culled from books, academic research papers, and a million other sources that most people are, to be frank, uninterested in directly consuming.
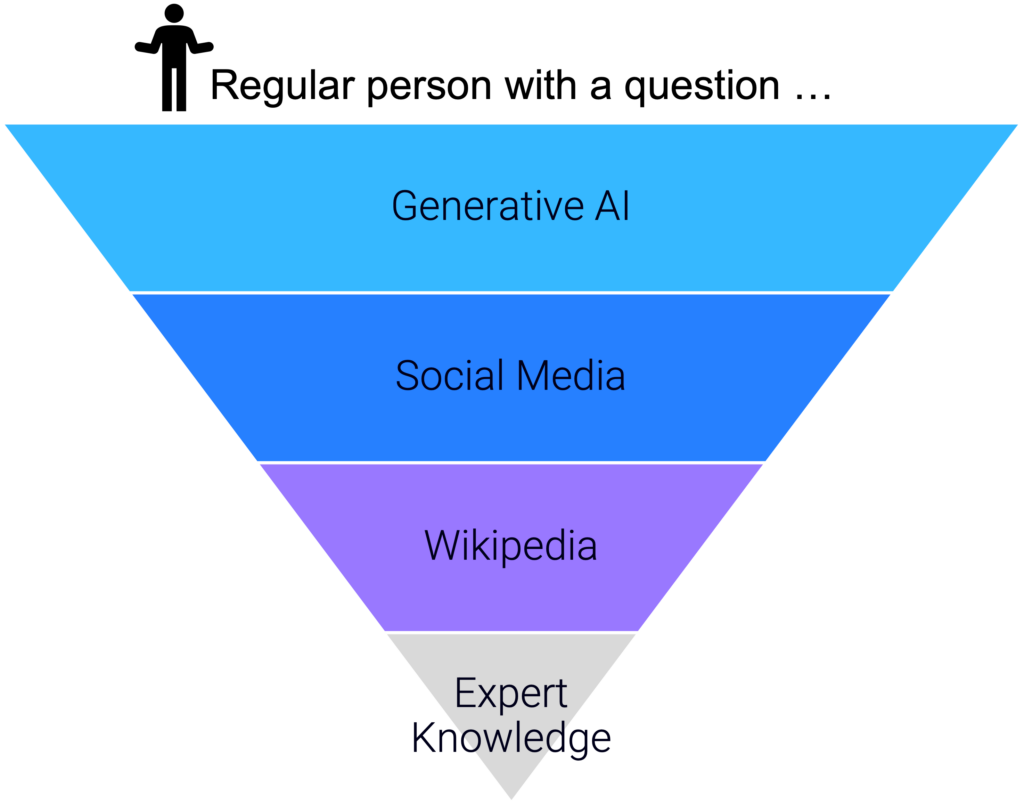
From a certain point of view, this whole thing can be seen as rather depressing.
The internet enables anyone to directly access most expert knowledge (you can actually read those academic research papers yourself!), but instead, we need it to be laundered through a series of intermediary layers, each designed to dumb it down and make it engaging enough to capture the 15-second attention spans of our modern, smartphone-addicted brains.
And, to make matters worse, each layer adds its own unique problems, which can’t ever be fully solved because they are inherent to the way the technology works. And these problems make trust challenging.
If anyone can edit Wikipedia at any time, how can we possibly trust it?
If anyone can become an influencer through social media (including and especially the All-In Podcast hosts), how can we ever trust it?
If generative AI will always occasionally produce plausible-sounding-but-completely-made-up responses, how can we ever trust it?
This is a point of view that you could have.
I, personally, do not.
I’m an optimist.
The Case for Optimism
So, what’s my case for being optimistic about the role of generative AI (and social media and Wikipedia) in disseminating expert knowledge, including financial advice?
Allow me to present it in three parts.
Part 1: Something is better than nothing.
According to a survey by Northwestern Mutual, U.S. consumers view financial advisors as the most trustworthy source for financial advice, and social media as the least trustworthy source. Interestingly, this holds true even when you isolate the data to just focus on Millennials or Gen Z.
And yet, according to that same survey, only 37% of Americans work with a financial advisor. And according to a different survey from Forbes, only 11% of Gen Z and Millennial Americans work with a financial advisor.
That same Forbes survey also tells us that 79% of Millennials and Gen Zers have gotten financial advice from … you guessed it! Social media!
This apparent contradiction really isn’t a surprise. Social media is where younger adults spend a lot of their time. And according to that Forbes survey, 69% of Gen Zers and Millennials report coming across financial advice on social media at least once a week. You almost can’t avoid it if you are sufficiently engaged with those platforms.
The real question is this – if you’re not going to make an appointment with a financial advisor, is consuming financial advice through social media better than doing nothing?
I’d argue that it is.
And those Millennials and Gen Zers that were surveyed by Forbes? They agree!
76% of millennials and Gen Zers think financial content on social media has made it less taboo to talk about money. 73% report that social media has improved their financial literacy. And 62% feel empowered by their access to financial advice on social media platforms.
Part 2: Skepticism isn’t a bad thing.
As we’ve already discussed, technologies like crowdsourcing, social media, and generative AI, come with plenty of problems that can imperil their ability to act as accurate and unbiased sources of knowledge.
The implications of this in financial services are obviously concerning. Incorrect information, self-serving advice, scams, and FOMO are all, unfortunately, landmines that need to be navigated around in today’s digital-first financial services ecosystem.
However, a small part of me can’t help but think that there might be a benefit to learning (sometimes the hard way) to avoid those landmines.
Growing up in the age of Google, Wikipedia, and Twitter, I’ve certainly learned to be a more skeptical consumer of information. Is it possible that this skepticism might end up being an advantage for consumers in their interactions with financial services providers?
Part 3: Adding layers to the stack makes the whole stack more valuable.
The pessimist sees each new layer in the expert knowledge stack as a replacement for the layer beneath it.
Why would someone read a book when they can glean the main points from Wikipedia? Why would they read that long-ass Wikipedia article when they can have Chat-GPT summarize it in two sentences in the voice of Dolly Parton?
The optimist (me) sees it differently.
The problem with expert knowledge, in its raw and unrefined form, is that it’s inaccessible and intimidating, like trying to descend a steep cliff with nothing to hold on to.

So, what we need to build are a series of more accessible, intermediate steps between the novice and the expert, tools to help people build their understanding and, crucially, build their confidence and interest in the topic, such that they will take the initiative to engage with it more deeply and sustainably.
Each layer that we add makes the entire stack more valuable.
Interestingly, some of the latest thinking in the world of AI-powered chatbots make this same case for a combined approach:
Jesse Dodge [a computer scientist at the Allen Institute for AI in Seattle] … points to an idea known as “retrieval,” whereby a chatbot will essentially consult a high-quality source on the web to fact-check an answer in real time. It would even cite precise links, as some A.I.-powered search engines now do. “Without that retrieval element,” Dodge says, “I don’t think there’s a way to solve the hallucination problem.” Otherwise, he says, he doubts that a chatbot answer can gain factual parity with Wikipedia or the Encyclopaedia Britannica.
Indeed, the folks at Wikipedia have already picked up this idea and run with it, having recently introduced a Wikipedia plug-in for ChatGPT:
GPT-4’s knowledge base is currently limited to data it ingested by the end of its training period, in September 2021. A Wikipedia plug-in helps the bot access information about events up to the present day. At least in theory, the tool — lines of code that direct a search for Wikipedia articles that answer a chatbot query — gives users an improved, combinatory experience: the fluency and linguistic capabilities of an A.I. chatbot, merged with the factuality and currency of Wikipedia.
The challenge for those of us working in financial services is how do we build this type of combinatory financial advice experience, leveraging the flexibility and engaging nature of generative AI (which we know consumers will lean on, whether they are advised against it or not) while slowly drawing users down to the more valuable (and monetizable) wealth management expertise that we’ve been selling for years?

